Authors: Baoqing Yue, Zihan Zhu, Yifan Zhang, Jichen Feng, Hufei Yang, Mengdi Wang
Venue: arXiv preprint arXiv:2603.04737 (2026)
PDF | arXiv | Project | Code | DOI
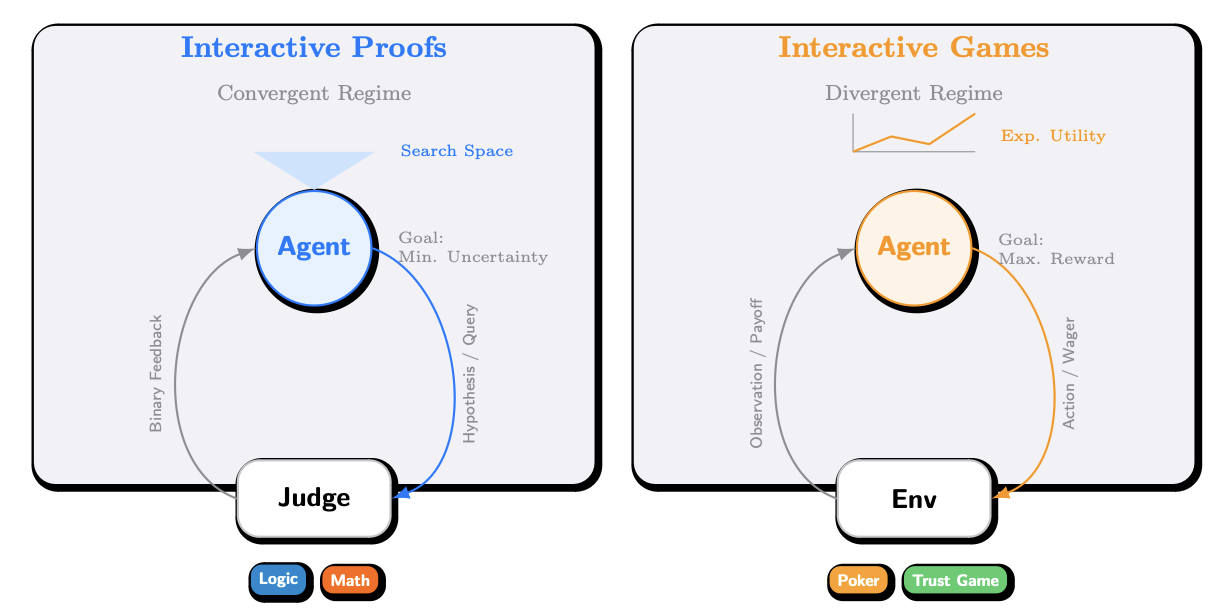
Interactive Benchmarks proposes evaluating model intelligence through constrained interaction instead of relying only on saturated static benchmarks. The framework measures how well a model actively acquires information under a budget, and instantiates that idea in two settings: Interactive Proofs, where models query a judge to solve logic and mathematics tasks, and Interactive Games, where models reason strategically to optimize long-horizon utility.
@misc{yue2026interactivebenchmarks,
title = {Interactive Benchmarks},
author = {Yue, Baoqing and Zhu, Zihan and Zhang, Yifan and Feng, Jichen and Yang, Hufei and Wang, Mengdi},
year = {2026},
eprint = {2603.04737},
archivePrefix= {arXiv},
primaryClass = {cs.AI},
url = {https://arxiv.org/abs/2603.04737}
}